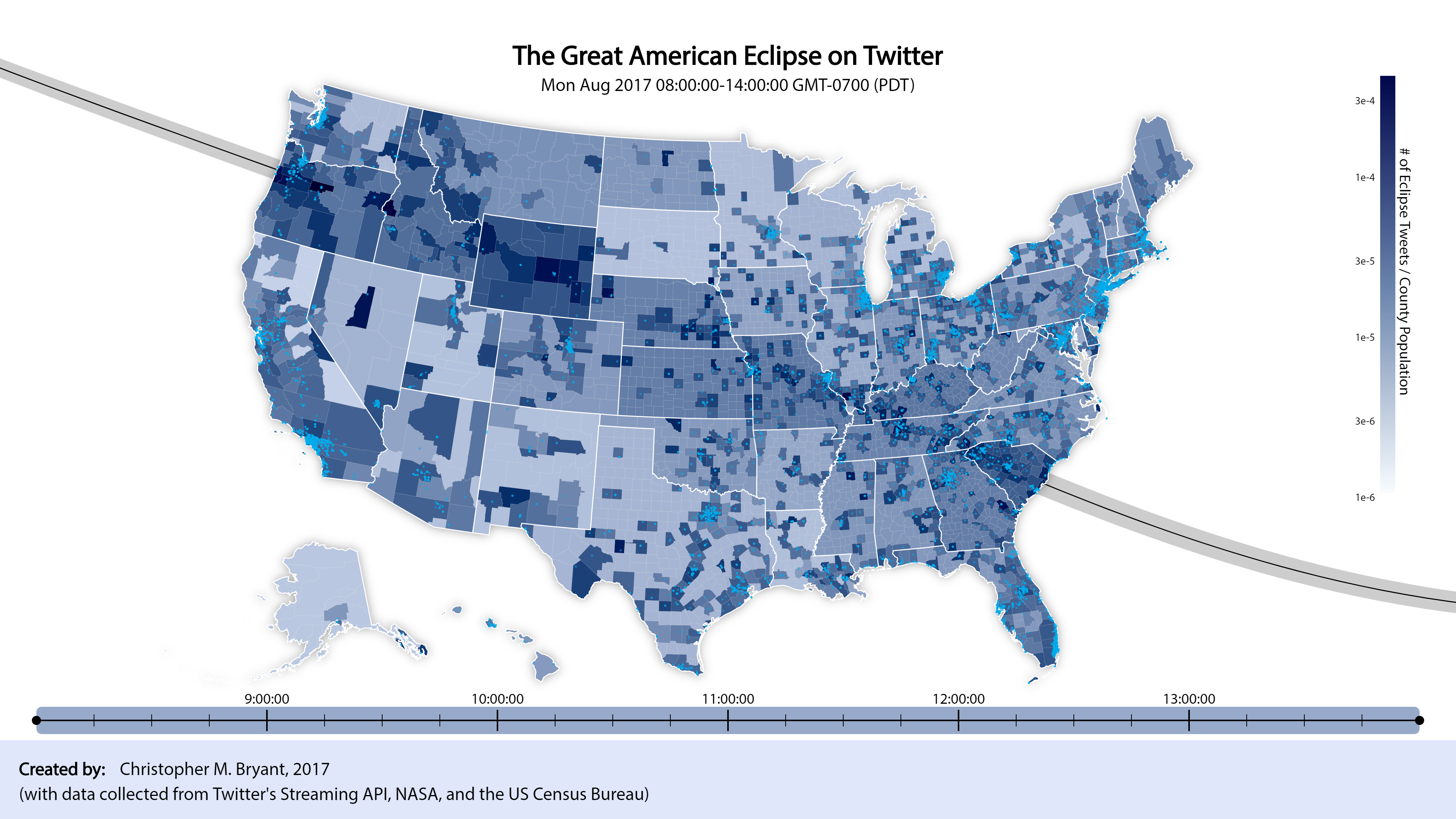
Click here for an interactive desktop version.
Twitter Eclipse Tracker:
Inspired by this Google Trends map of eclipse searches in the week leading up to the “Great American Eclipse” of 2017, I decided to see if I could track the path of the moon’s shadow as it crossed the continental United States by using only Twitter mentions of the eclipse.
Intro - August 18, 2017:
I am working on writing a program to mine Twitter data from August 21, 2017 (about 9am PDT to 3pm EDT) for mentions of the solar eclipse to see if by using frequency of mentions alone, we can track the path of the moon’s shadow throughout the day. Using this data, I hope to generate a changing map of the United States with counties shaded according to proportional tweet volume referencing the eclipse. I will also compare this path to the true path and see if there are any interesting conclusions to be made (Twitter-mentions lagging behind or anticipating the eclipse, Twitter-shadow-area compared to the actual region of totality, tweet content of partial eclipse experiencers vs total eclipse experiencers, etc.)
The rate-limiting of the Twitter REST API is too restricting for the type of large data-acquisition this project requires, so I will try to write up and test a Python script which will use Twitter’s Streaming API to collect data live during the eclipse. Since I will have no internet access in Mitchell, OR (where I will be viewing the eclipse from), I will leave a computer running the program at home to automatically collect the relevant Tweets. I will not be able to monitor the progress of the program during collection, so I will program in fail-safes to ensure that the total data collected as well as the size of each data file does not get too large. Hopefully, I can get it done before I leave for the airport early tomorrow morning.
UPDATE - September 4, 2017:
Success! The data set (eclipsefile1.json) is smaller than expected, but it looks like the program did what it was supposed to do!
Now home from my extended eclipse-trip, I am beginning the process of figuring out how to process and map my data. I just posted the EclipseTracker.ipynb Jupyter Notebook which collected data from Twitter’s streaming API while I was away. It appears that roughly 1M tweets in the 6-hour data acquisition period mentioned either the word “eclipse” or “sun,” of which 20,933 were geo-tagged. A quick scatter plot of each of these geo-tagged points on an (X, Y) = (Longitude, Latitude) chart reveals an image which strikingly appears to match the population density of the United States, but with an added faint trail of points crossing the country in the path of totality.
{kind=link}
Moving forward, I will work to bin these points by county (probably using TopoJSON to create the county map) and normalize each measurement by dividing the tweet-count by the county population. Hopefully, this process will accent the path of the eclipse amidst the Twitter noise.
Some other things took into:
- using the Albers projection to accurately preserve county area;
- obtaining and plotting the NASA eclipse path data;
- creating a time-series of images to display shadow movement.
UPDATE - September 12, 2017:
Since my last update, I have created the beginnings of an interactive choropleth of the United States to visualize the Twitter data I collected. My workflow, outlined below, has been divided into two categories: data processing (done mainly in Python) and data visualization (done mainly in JavaScript).
Data processing:
County Identification
Because of my desire to plot my data as a county choropleth, I faced two main challenges: determining which county each tweet was sent from based on its geographic coordinates, and making those county labels compatible with whatever system I would use to plot those counties. Since the geo-tagged Twitter data I collected has relatively inconsistent contents in its “Place” field, with geographic identifiers ranging from as precise as a specific street address to as general as the country from which the tweet was sent, I focused on using the bounding box which was present in the same form in every geo-tagged tweet. This box is a collection of 4 [Longitude, Latitude] pairs which define the vertices of the smallest box enclosing the entire specified region. (Note that while both Twitter and GeoJSON encode their coordinates in this [Lon, Lat] order, it is opposite the ISO 6709 standard of [Lat, Lon].) To approximate the bounding box as a single location, for each tweet, I simply averaged the four points so that a bounding box enclosing a city, for example, became a coordinate at the center of the city. This approach obviously has some issues, such as the fact that a bounding box around Florida becomes a point sitting in the waters of the Gulf of Mexico. Rather than fix those issues in some sophisticated way, however, I decided to just omit those problematic points from my dataset. (I should have realized sooner that this decision would cause more problems down the road . . . see “What have I done wrong?” below).
I quickly learned that each United States county has a unique 5-digit numerical identifier called a FIPS county code, the first 2 digits of which represent the US state (or territory, region, etc.), and the next 3 of which represent the county or county-equivalent we’re identifying within that state. I also determined that to plot the US counties, I would need to use either a GeoJSON or TopoJSON file (which both use the JSON file format to encode the shape of geographic objects, each of which can be labeled by their identifying FIPS code).
The concrete goal I faced now was to convert the list of averaged coordinates obtained from the tweet bounding-boxes into FIPS codes. I played with the idea of creating some sort of algorithm to determine whether a point lies within a multipolygon, but I instead opted to use the reverse geocoding API offered by datasciencetoolkit.org. For each point location I submitted, I received the corresponding county information. Because the API has some fuzziness built into its algorithm “to combat errors caused by lack of precision,” if the point happens to be located near a border, the API returns information on all possible counties the point could lie within.
Color Mapping
To create the set of values that I would map to color in my choropleth, I tallied up the number of tweets sent from each county (and if the tweet had multiple associated counties, its one tally would be divided evenly among all those counties; e.g. if the point was near a meeting of 4 counties, each county would receive 0.25 tallies) [I discovered later that this even division is not the optimal way of distributing tallies!]. Tally counts are bound to be higher in places with a higher population, so to get a more useful set of data, I need to divide the tally count by the county population, yielding an intrinsic dimensionless property for plotting. This quantity can be more meaningfully plotted on a choropleth since it is independent of county population or county size. The most recent population data I could find from the US Census Bureau API is from July 1, 2016, but the current data should not have changed much in the year that has passed since then.
After making a histogram of number of counties vs. county population, I determined that county population resembles a log-normal distribution (which can be visually confirmed by taking the log of county population to reveal a roughly normally distributed number count). Indeed, according to Gilbrat’s Law, like many other results of growth processes in nature, city size can be described by such a distribution. In the same way that additive processes of random variables generate a normal distribution by the central limit theorem, multiplicative processes generate a log-normal distribution by a multiplicative version of the same theorem.
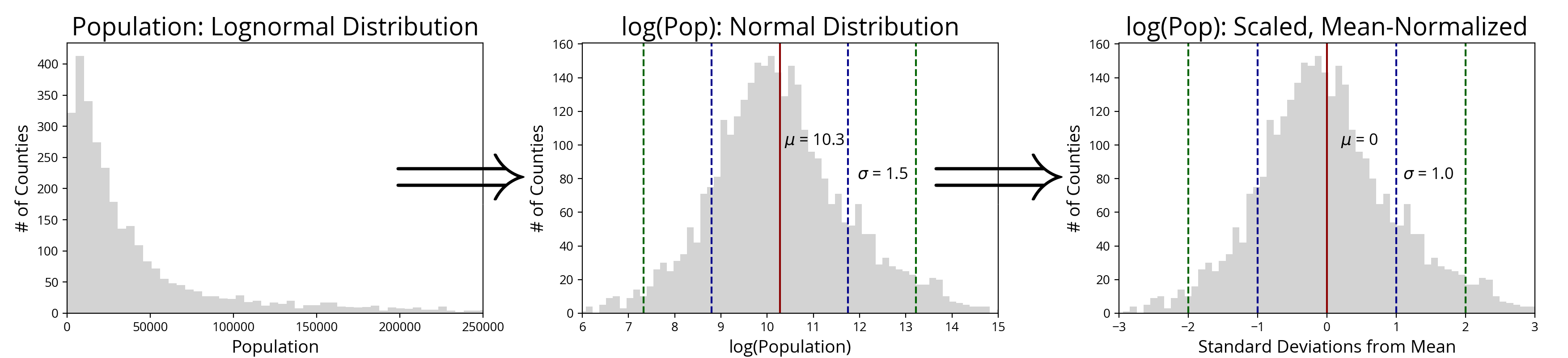
While we’re making histograms, we can also look at the tweet tally data. {UPDATE – September 20, 2017: The tally counts displayed below were retrieved from the tally distributions calculated in the final analysis. Here, we see that the distribution looks slightly bimodal, but otherwise, it is pretty close to Gaussian. This bimodal shape arises because many counties only received partial tallies from tweets with state-wide geotagging uncertainty (creating the lower lobe), whereas the others all received at least one tally from a precisely tagged tweet (creating the upper lobe)}.
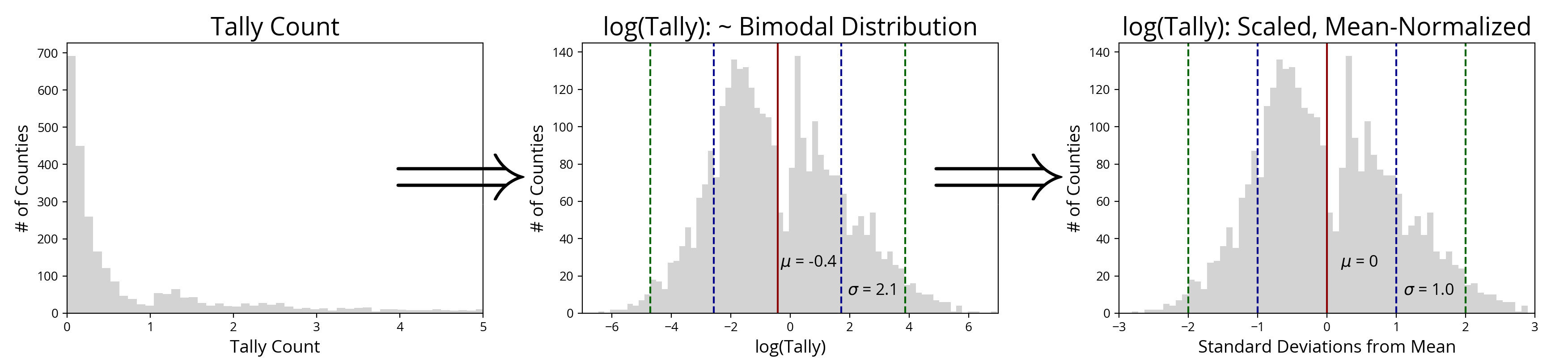
Though it is nice to see that tally counts also follow a mostly log-normal distribution, as discussed above, we will be plotting the ratio of tallies to population in each county, not tallies alone. To estimate what this distribution of ratios should look like, we can begin by realizing this: if tweeting were a statistically random occurrence among the United States population, average tweet count in a county would be exactly proportional to that county’s population. Dividing the tweet count (per county) by county population would yield a constant. However, the trend we are trying to illuminate is a deviation from the usual Twitter landscape, a perturbation on this exact proportionality. Since county population fits a log-normal distribution, any anomalies in the tweet/population proportionality should also show up as also being roughly log-normally distributed [CITATION NEEDED]. Thus, by taking the logarithm of our tally fractions derived from eclipse tweet counts which we expect display anomalous behavior, we should find a normal distribution of data. While the results (below) are messier than before, the distribution is close enough to log-normal that any imperfections do not have a major impact on the color-mapping we will soon perform {UPDATE – September 20, 2017: Like above, the tally data displayed here comes from the final tally analysis}.
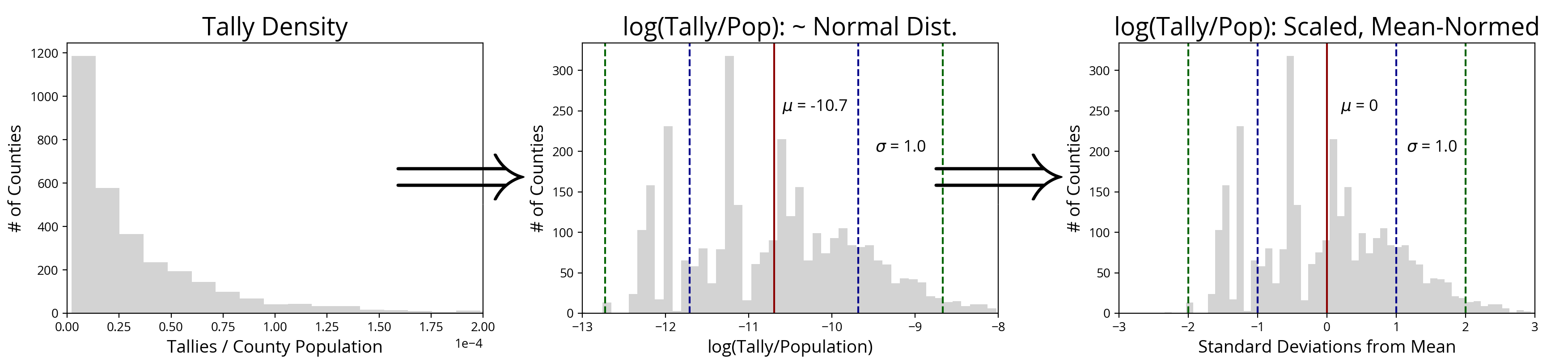
We want the data for the choropleth to be normally distributed because this will allow us to obtain good visual contrast across the whole range of data. For example, if we want the choropleth color to range from black to white, we can map the data’s mean to the middle gray, two standard deviations below the mean to black, and two standard deviations above the mean to white, encompassing a total of about 95% of the data, smoothly transitioning from the lowest to the highest data value in that range. If we wanted to encompass more data, we could stretch our color range out to 3 standard deviations in each direction, but for just an extra small percentage of included data, this would undesirably reduce the contrast in the central region of data (where most of the data resides). In this general grayscale model, for greater contrast, we shrink the range of data encompassed, and for greater brightness, we decrease the center value of that encompassed range. I find that a 2-sigma (2 in each direction), mean-centered, color mapping provides the best results.
Data visualization:
Making a Map
After trying to create my map with a variety of Python tools (e.g. Plotly, Shapely, Basemap) with little success, I decided that using the “Data-Driven Documents” JavaScript Library D3.js would be my best path forward. This library is capable of building beautiful highly-customizable interactive visualizations (look at some of these examples!—I’m particularly impressed by this one), has great GeoJSON/TopoJSON support, and already has a large amount of material online with viewable source code. The last item on that list has been incredibly important, since, before I started this project, I did not know any JavaScript, HTML, CSS, or XML. After a day working through the Codecademy courses on JavaScript and HTML, I transitioned into climbing the steep learning curve of D3 by trying to replicate the results of existing data-bound choropleths (which also was made more difficult because, while I used d3.v4, much of the example material used the older version d3.v3).
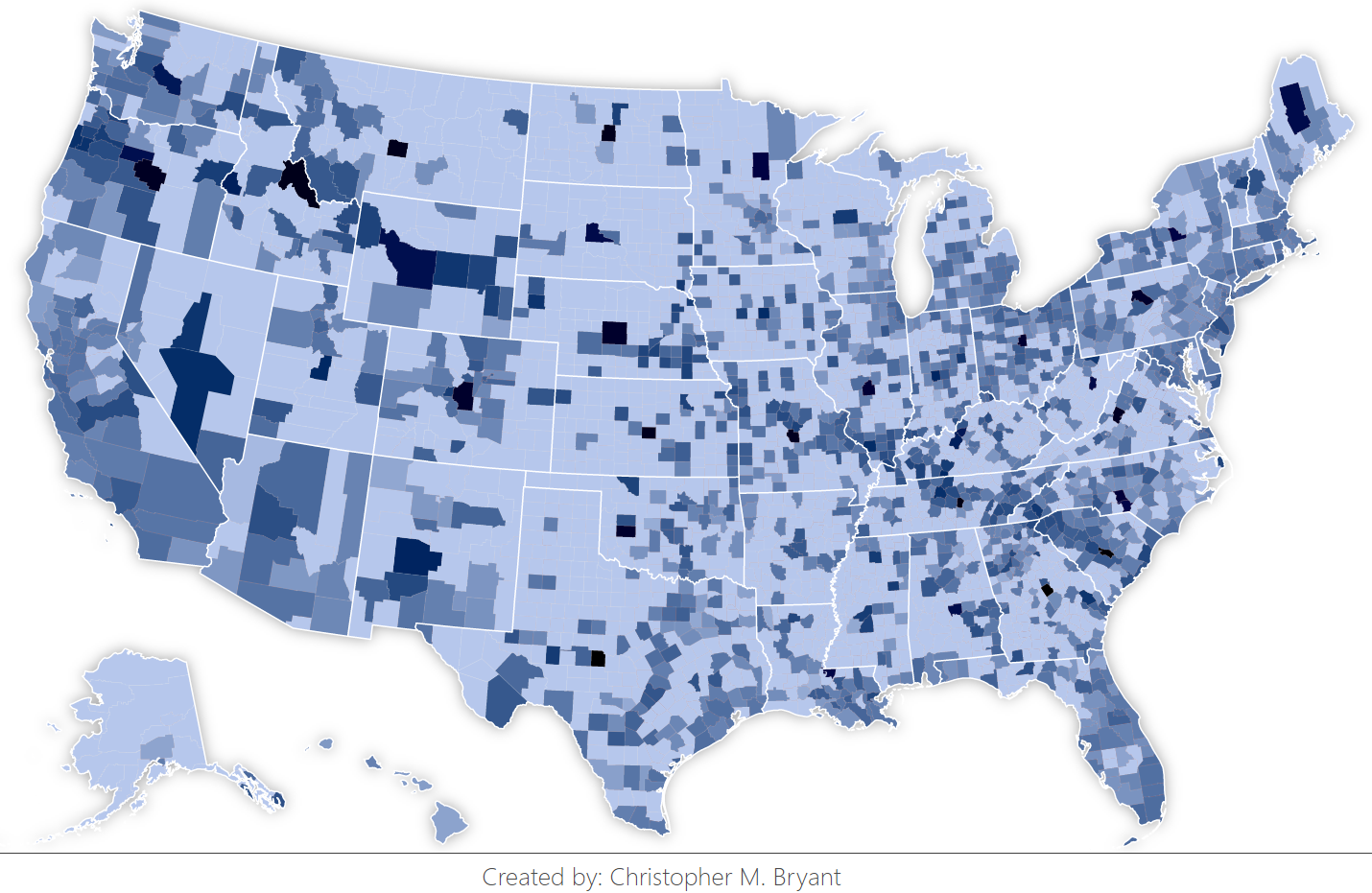
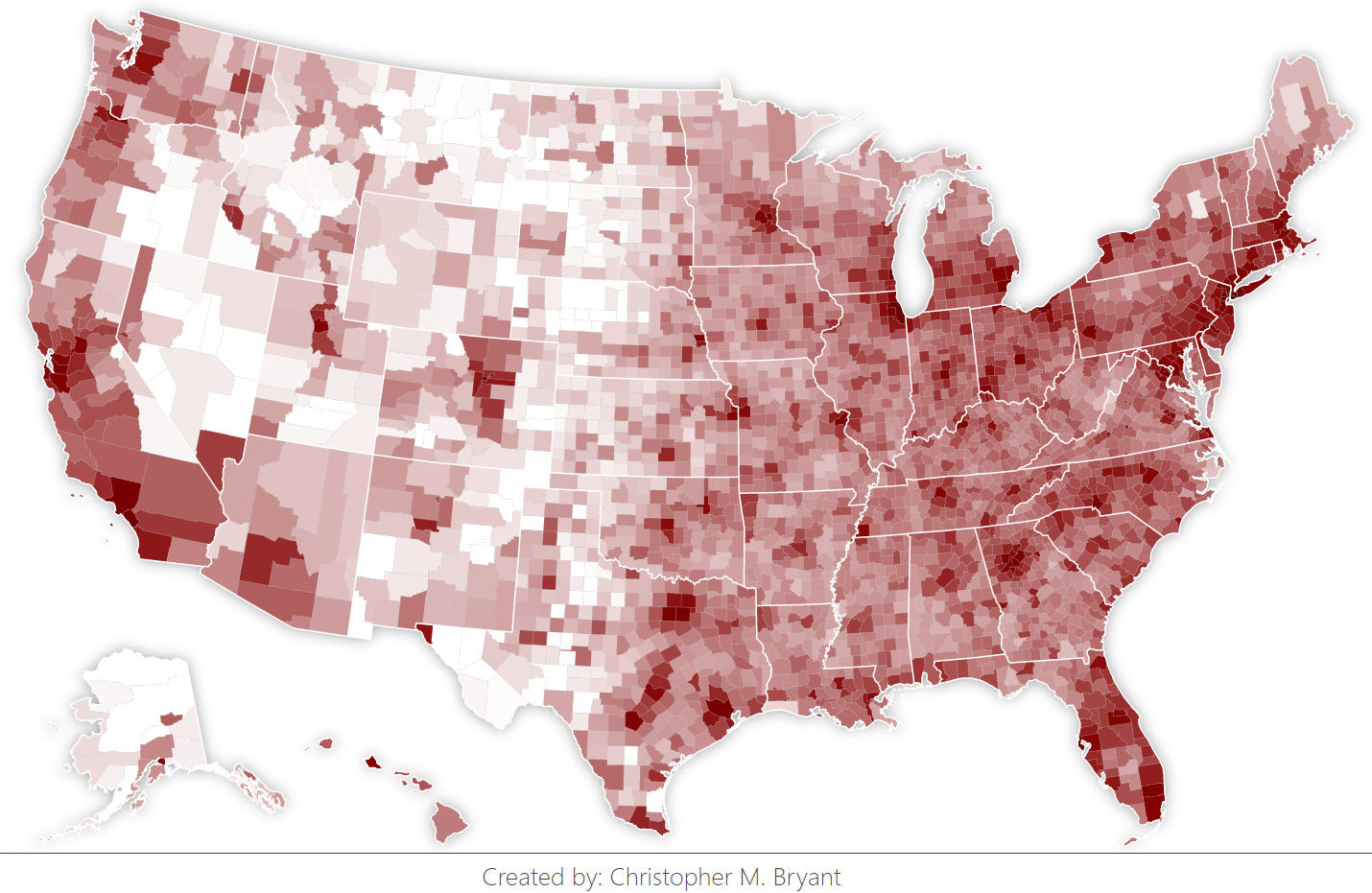
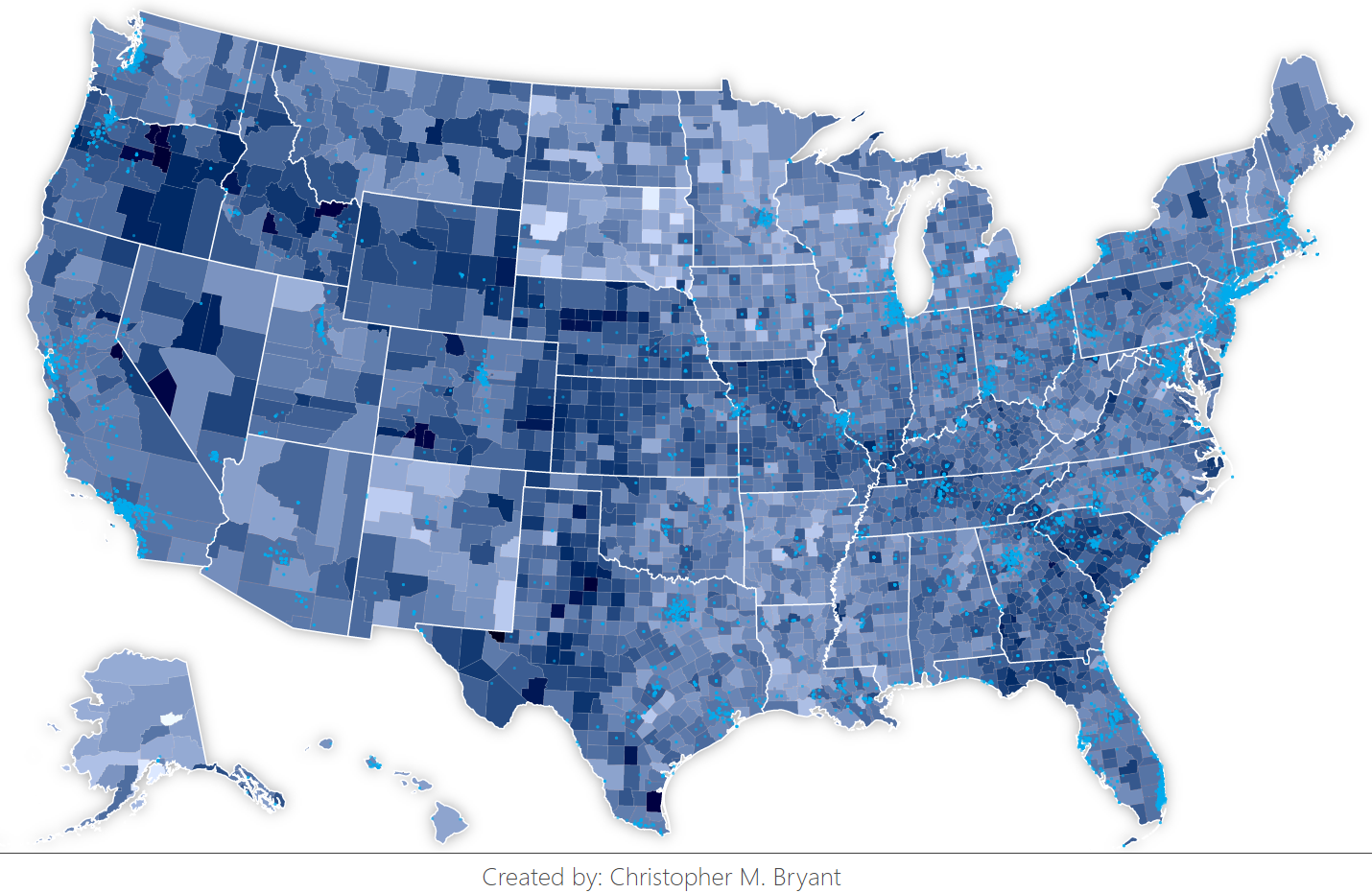
Eventually, thanks in large part to this tutorial by Venkata Karthik Thota, and with stylistic influences from this example, I got my choropleth of Twitter data up and running (darker blue is greater eclipse-tweet-fraction). Additionally, by using a technique I saw in this example for computing path area, I was able to combine my county population data with computed county area to generate the population density choropleth below (darker red is more populated).
{kind=link}
Visualizing Statistical Error
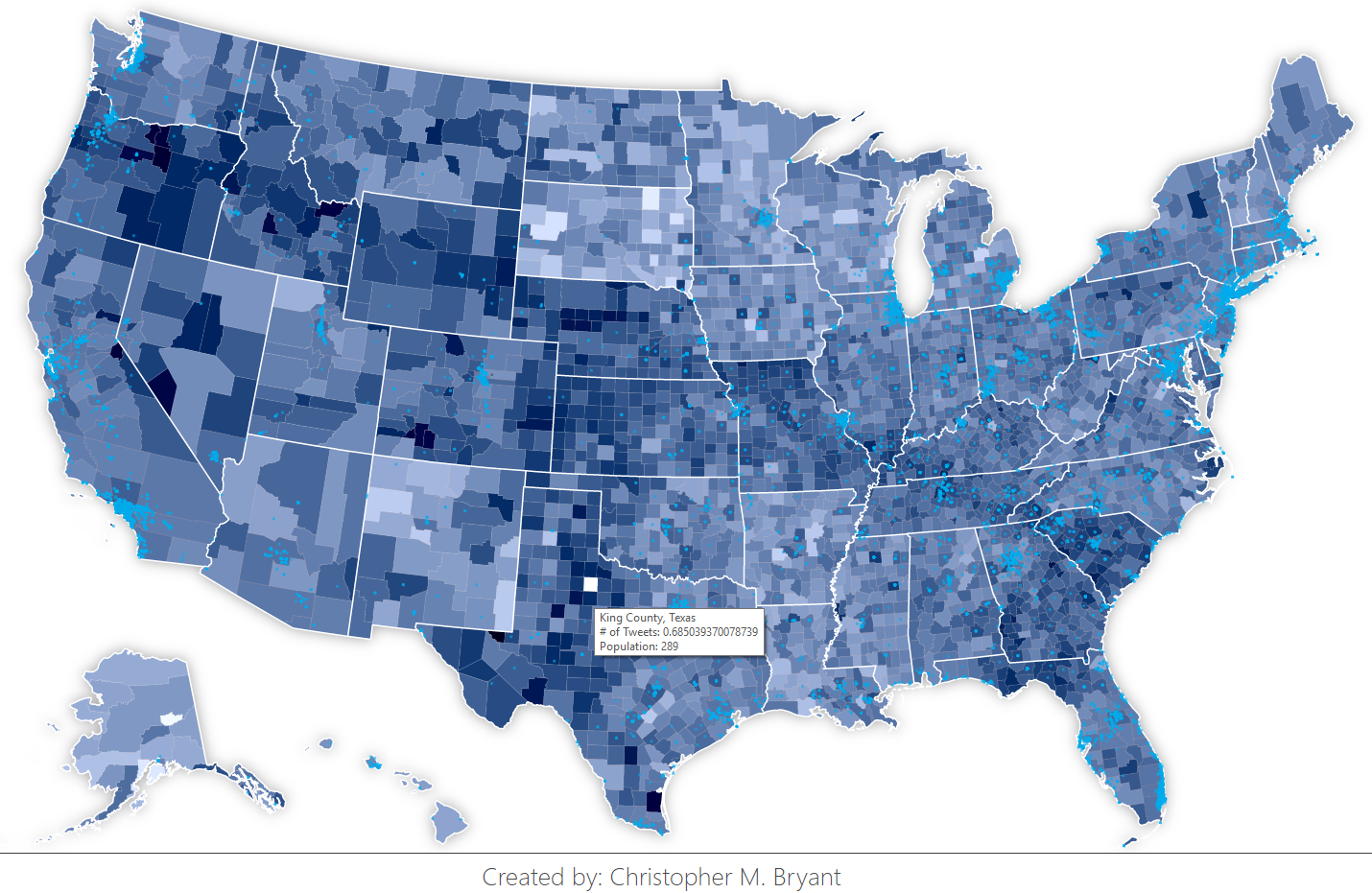
Some counties are bound to have anomalously dark or light color values because the sample size is so small (small counties result in more coarsely quantized tweet fraction values since each Twitter user makes up a larger percentage of that population than he or she would in a larger county). As a result, counties with low population density have a higher error than counties with a high population density. To encode this information into my visualization, I overlayed the tweet data choropleth on top of the population density choropleth in the interactive version so that if I hover my mouse cursor over a county, the population density color is revealed. I think this nicely allows the error estimates to be visually accessible to a viewer without distracting from the main data.
What have I done wrong?
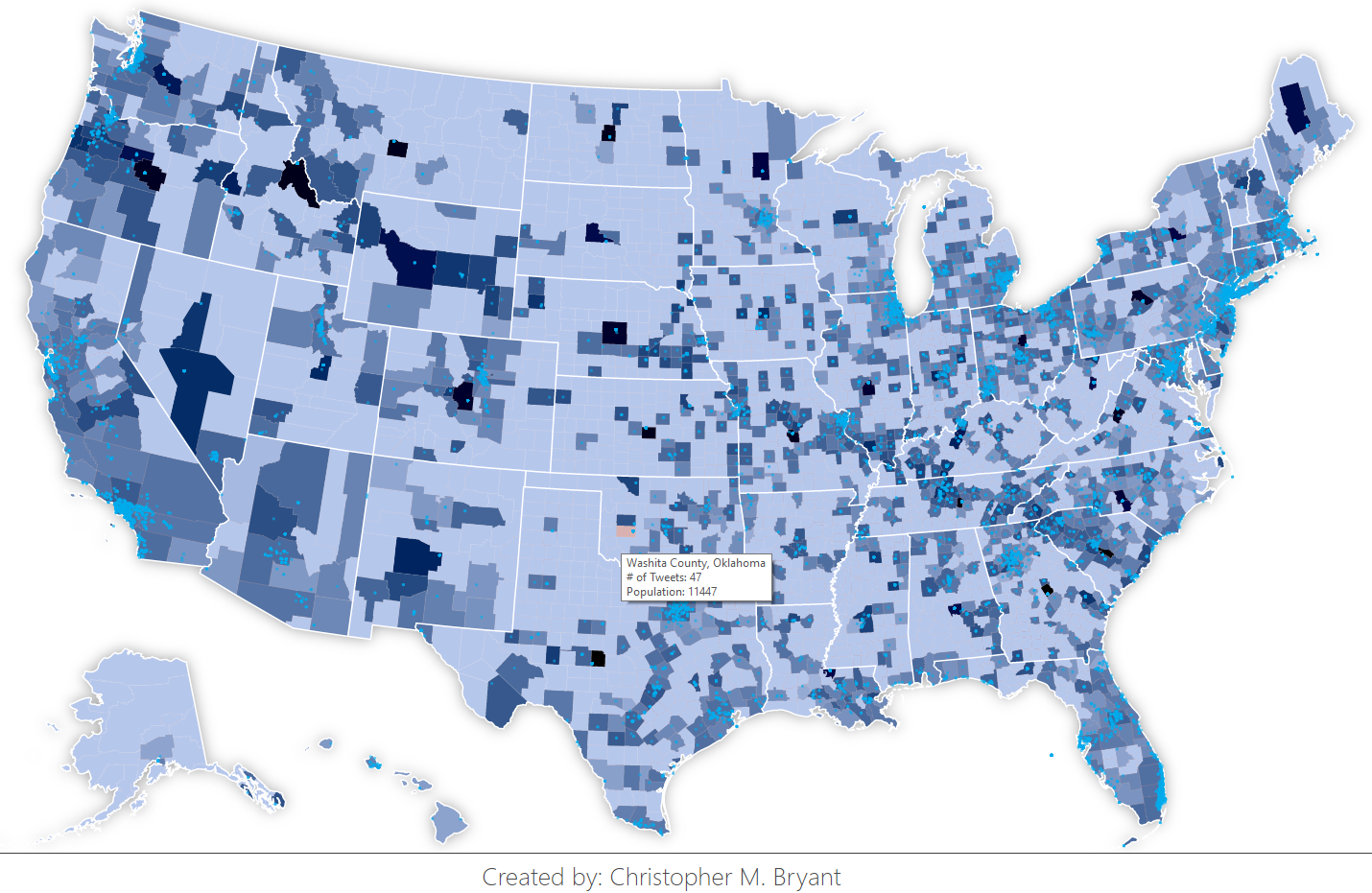
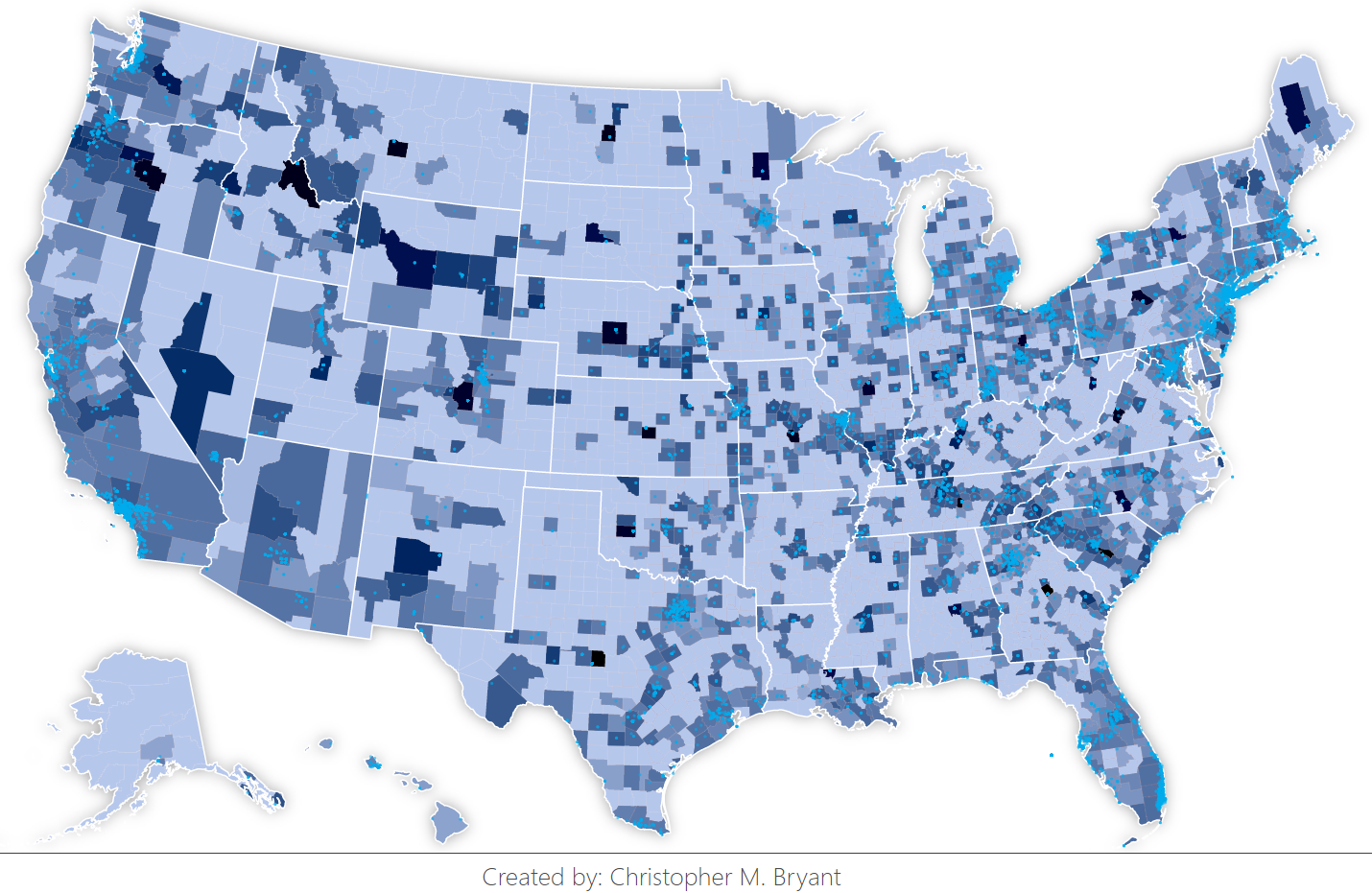
Lastly, I encoded each individual tweet as a point in a GeoJSON file so that it could be plotted on top of the TopoJSON-based choropleth. A great resource for quickly viewing a GeoJSON or TopoJSON file (especially if you just need to check to make sure that the file is encoded properly) is mapshaper.org. [An aside: the US County TopoJSON provided by d3js.org already has its values mapped according to the US Albers Projection, so I had to play with the scale of my GeoJSON Albers Projection mapping until I found the scale value which matched the pre-coded scale of the TopoJSON file—it’s 1280, by the way]. Once I plotted all my tweets as a new map with points overlaying my choropleth (shown below), I realized the mistake I had made earlier in simplifying the tweet coordinates. In nearly every state on the map, there is an anomalously dark blue county which apparently has a large number of tweets all being sent from the exact same location. Upon further inspection, I realized that this location was precisely the center of the state’s bounding box. See here, this one dot representing 47 tweets right at the center of Oklahoma’s bounding box. If I want a more accurate visualization of my eclipse data, I am going to need some way of accounting for the tweets with bounding boxes larger than the size of a county.
{kind=link}
Moving Forward:
To fix the bounding box failure, I am going to reassign tally counts by treating each problematic tweet as though the reverse geocoding API had returned every county in that state. To do this, I will parse through the Twitter data and select every tweet which has its place type tagged as “admin” (note: the tag options are “country”, “city”, “admin”, “neighborhood”, and “poi”; I will just throw away points tagged “country” since they might as well not be geo-tagged at all). Some of the “admin” values are cities for some reason (e.g., “Denver CO”, “Charlottesville VA”, “Jacksonville FL”, etc.), but most are states (e.g. “Hawaii, USA”, “Oklahoma, USA”, “New York, USA”, etc.). Every state value (and “District of Columbia”) ends in the string “, USA”, so it will be easy to extract only the tweets with state-level geo-precision. To assemble my new tally count, I just need to map state name to state FIPS code (using this helpful resource), find all other FIPS county codes which begin with the same two digits, then divide each tally evenly among all those counties {[UPDATE – September 20, 2017]: Again, “evenly” is not the right approach. See correction.}.
Once the bounding box issue has been resolved, I will create a GeoJSON file with the NASA eclipse path data, and overlay that on the map (I hope to create a few buttons to toggle which layers are visible so that the map does not become visually cluttered). After that, the next big challenge will be to bin all of my data by time and create an interactive slider object in JavaScript so that the time-dependence of the national Twitter eclipse activity can be viewed.
UPDATE - September 20, 2017:
Tweet Tally Distribution - Corrected:
After some more experimentation, I have come up with a tally-distribution procedure which I think is statistically fair.
To recap, the goal of this project is to visualize how Twitter activity during the eclipse differs from Twitter activity on a typical day. If we assume that there is no relationship between the characteristics of a person and their likelihood of posting a geo-tagged tweet, a random collection of tweets sent from within the US is essentially a random sampling of the US population (yes, this assumption simplifies subtleties of Twitter dynamics and user tendencies, but it will do fine for our geographic analysis). As such, a statistically random collection of tweets will be distributed spatially across the country according to population density (i.e. if more people live in a location, more tweets in our sample will have come from that location). While population density might be an interesting data set to visualize in some circumstances, we need some way to leave it out of our current visualization so that any anomalous activity from the eclipse can rise above the noise. In other words, we need a way to visualize the data such that if our data truly was a statistically random sampling of the population, the choropleth would be completely uniform in color.
Earlier, I tried to accomplish this by coloring each county according to the ratio of tweet count to population, but as became apparent, this only works well if we know precisely which county each tweet came from. If a tweet has uncertainty in its location, possibly coming from more than one county, we need some way to split up a single tweet between all its possible locations. What I have now realized is that this splitting needs to be done unevenly: i.e., according to population density.
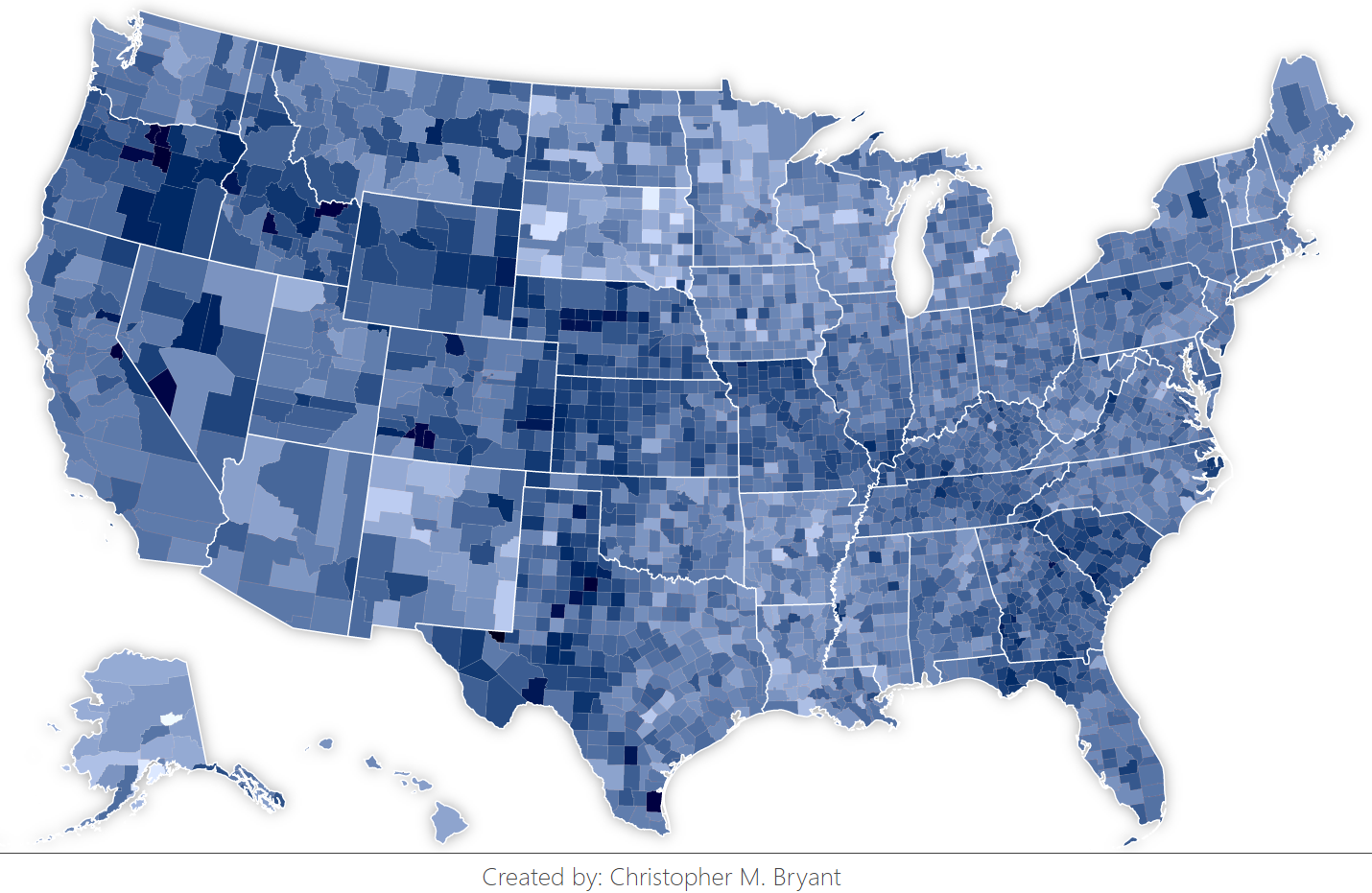
If each tweet of uncertain county origin is split evenly between all its possible counties, we end up actually inadvertently encoding the inverse of population into our visualization, as can be seen in this visualization attempt below. In addition to the clearly visible eclipse path running from coast to coast, a new dark leg protrudes through the west side of Texas. After superimposing the known tweet locations, it seems unlikely that this new leg accurately represents the actual tweets. By closely inspecting some of the particularly dark regions, we can see that the regions are dark not because they have an abnormally high tweet count, but because they have an abnormally low population for their size. Referring back to the population density choropleth, we see that the extra dark leg of the tweet map matches the low population-density area of the middle of America stretching down through the western portion of Texas. We can understand this phenomenon by considering what our map would look like if none of the tweets were geotagged and yet we still tried to split each tweet evenly between every county in the United States. Since the plotted color is a function of {tweet count / county population}, counties with higher population would have lower values and counties with lower population would have higher values, generating a choropleth of (population)-1.
{kind=link}
{kind=link}
To counteract this effect, each tweet of ambiguous origin should be divided proportionally by how much each county contains of the total population in the total collection of possible counties. Specifically, to keep a uniform color distribution of ti / pi for each county i in the collection of N considered counties, where ti is the amount of a tweet tally received by county i and pi is the population of that county, it must be the case that ti = pi * (T / P), where T is the value of a single tweet tally (i.e. T = 1) and P is the total population of the considered counties, since this both is dimensionally correct and meets the requirement that the sums of ti and pi, respectively, are T and P. As a result, for each additional tweet tally added ambiguously to a collection of counties, each county in the collection darkens by the same amount.
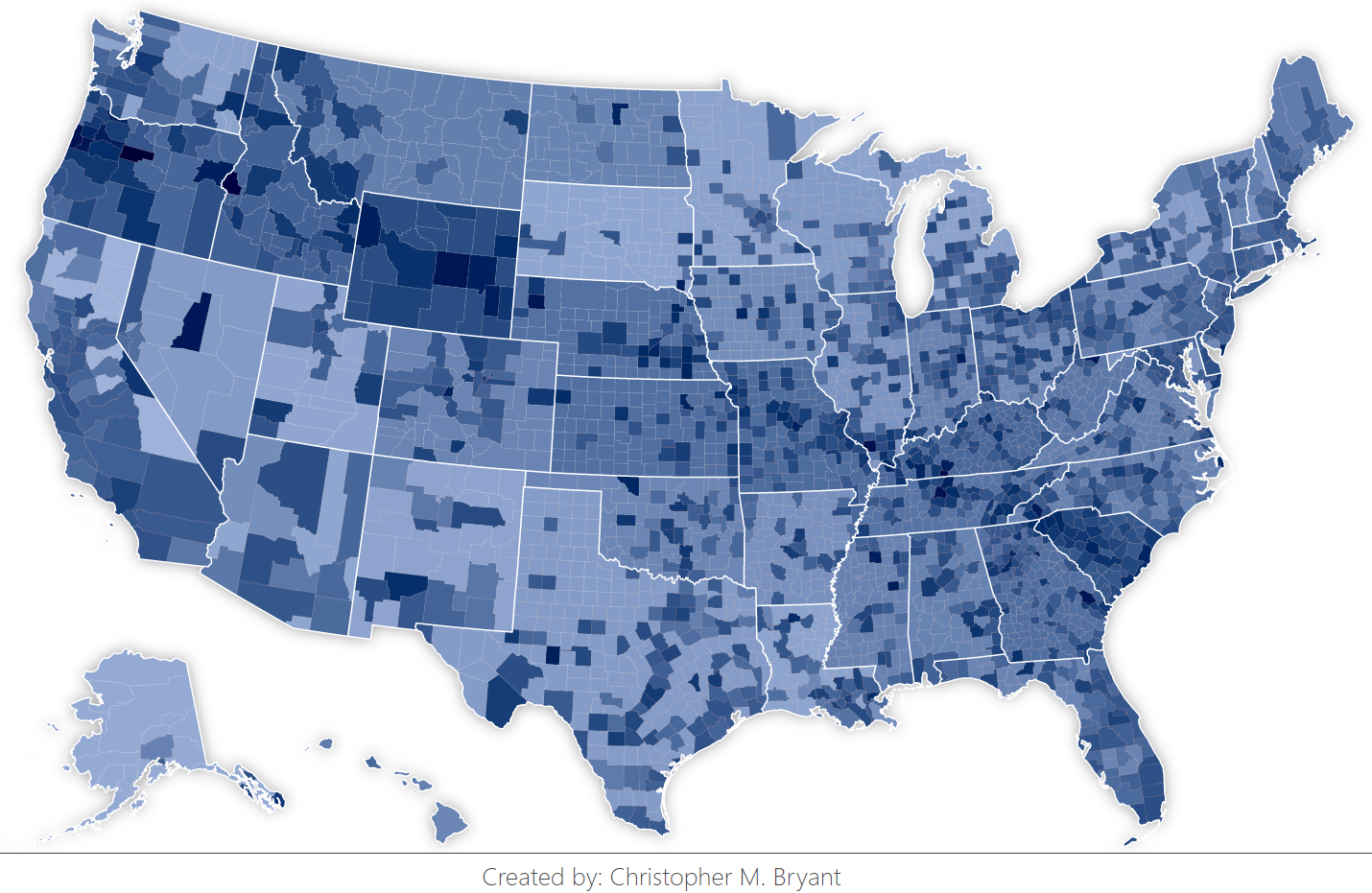
With this distribution employed, the plot above emerges which retains much of the smoothing effect caused by tally-sharing, but without the additional dark leg seen in the previous plot.
NASA Eclipse GeoJSON:
By using regexes to extract relevant information from the eclipse path datasheet published by NASA, then converting their degrees-decimal-minutes coordinate system to GeoJSON-compatible decimal degrees, I created a GeoJSON encoding of both the centerline of totality and the northern- and southern-most regions of totality.
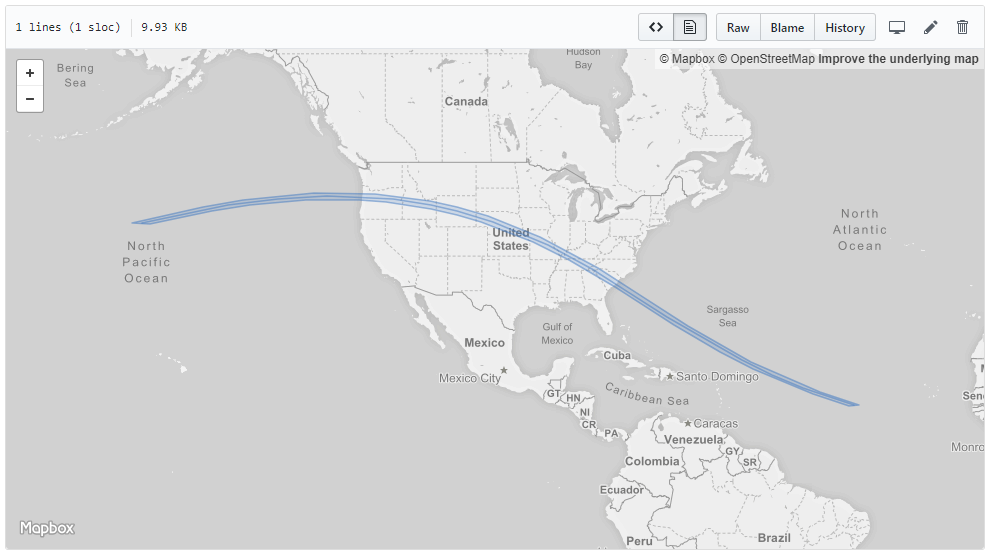
The most difficult part of this process was actually getting the shape to render properly in the SVG with the rest of my Geo/TopoJSON objects. The US county path data is encoded in TopoJSON pre-projected into the Albers USA projection, while the tweet point data is encoded in GeoJSON with no projection. Since the Albers USA projection pulls Alaska and Hawaii from their proper positions to fit nicely in the image (as well as scaling Alaska by a factor of 1/3), the tweet GeoJSON also needed to be projected into Albers USA to match. However, the eclipse path had to be projected into plain Albers, otherwise it would be cut off shortly after crossing into the oceans on either side of the country. Getting all three projections to match up amounted to a bit of educated guess-and-check until each data set was properly aligned.
Creating a Video:
To visualize the changing tweet activity over time as a video, I modified my Python script so that before tallying up tweet counts, it bins the data by time, then outputs an array of tally counts for each county (rather than a single value). It calculates the mean and standard deviation of all the values in all the arrays once it has finished populating those arrays so that it can standardize the color normalization from frame to frame and save the values to a file. In turn, I modified my JavaScript to access the data from that file for all the counties just one array index at a time, thus plotting one frame at a time. Separating the tasks of calculation and plotting like this allows the individual image frames to plot much faster than they would if, in addition to plotting the color values, the JavaScript code also had to calculate what values to plot.
Ideally, if my Twitter dataset were infinite in size, each video frame would contain data only from a single instant in time and the video would be able to change in real-time. Unfortunately, my roughly 20,000 tweets collected over the course of 6 hours make a rather small sample size, so instead, to see anything useful, each frame must consist of data from a relatively large time interval. I have elected to employ a method of plotting similar to a simple moving average, such that in any given plotted frame, the plotted tally data comes from a block of time ΔT which is shifted forward in small time increments dt for each new frame. For example, if dt = 2 min and ΔT = 60 min, then frame 1 of the video plots data from t = 0 to t = 60, frame 2 plots data from t = 2 to t = 62, frame 3 plots data from t = 4 to t = 64, and so on. The smaller we make dt and the larger we make ΔT, the less of a change we should see from frame to frame. The larger ΔT is, the less noisy our plot is, but also the greater our uncertainty in the relationship between the plot and the time at which the plotted data refers to. The only tradeoff for dt seems to be that the smaller dt is, the more frames we can create, but the larger our output file size becomes. Choosing dt = 2 min and ΔT = 60 min seems to be a good balance for the current project. A full video of these frames (at 29.97 fps) can be downloaded here, but I find that the visual changes over time are easier to see in a faster, looped version, so here is a gif version of the video (time-remapped with an easy-ease transition in Adobe After Effects):
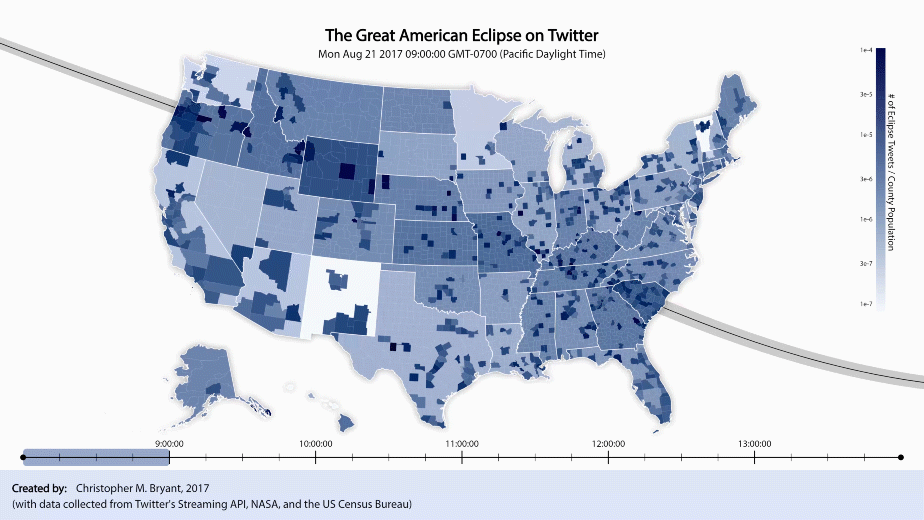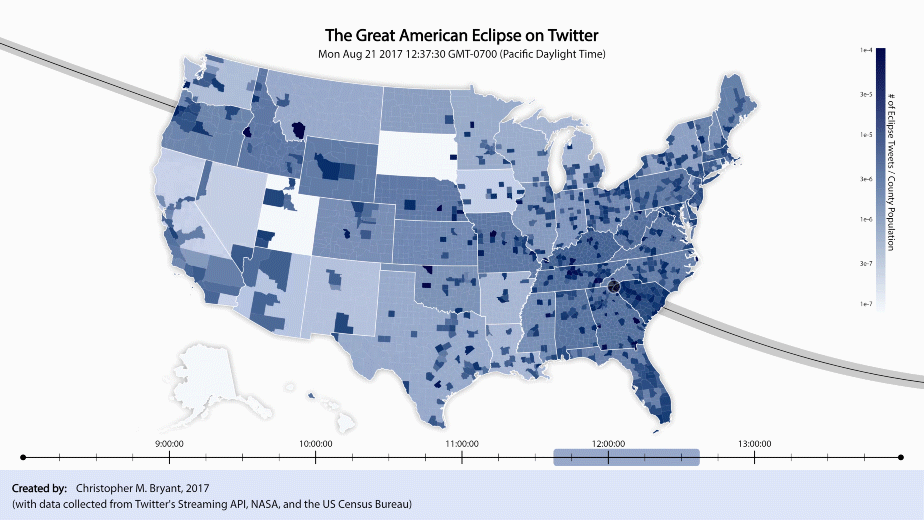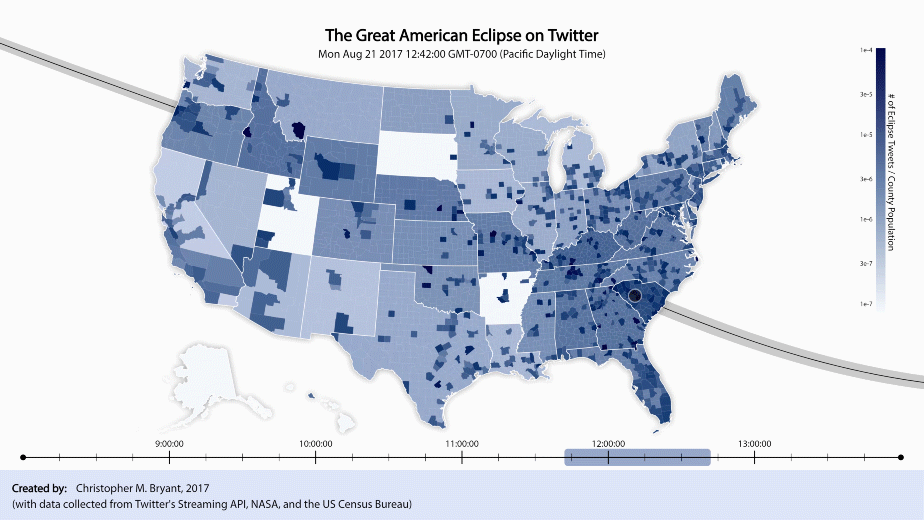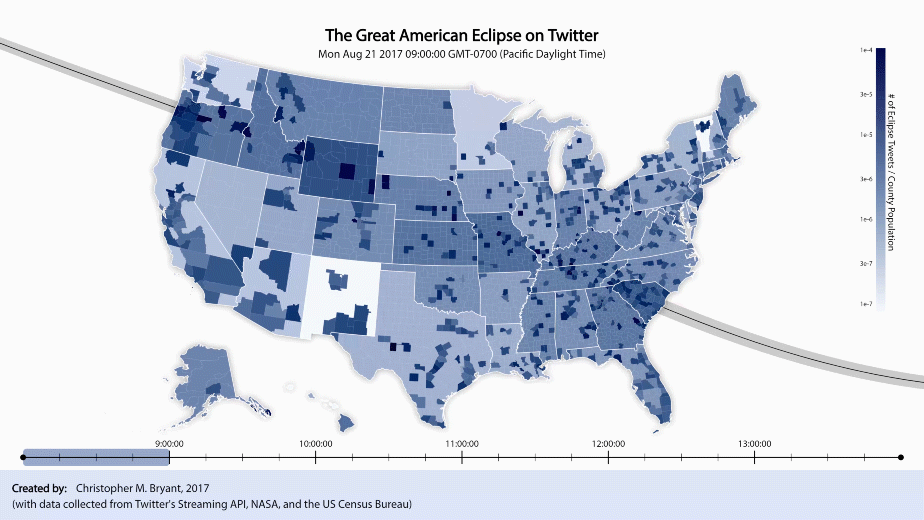
The sliding blue bar at the bottom indicates that only data from within that window of time is being plotted. As the bar sweeps from left to right, a pair of black circles move along the path of totality across the country. The left and right circle, respectively, depict the approximate regions of totality at the times indicated by the leftmost and rightmost end of the sliding blue block. (The region is only approximate because although the circles are correctly centered at the point of maximum totality, the shadow actually cast by the moon is more elongated and jagged).
At this time-scale, while the path of totality is no longer obvious to the naked eye, new effects of the partial eclipse have become apparent. As the circles sweep across the country, we can see a large shadow move along with them. The shadow’s leading edge is less apparent than its trailing edge, however, since the country is relatively dark to begin with, but lightens dramatically after the eclipse has passed. It appears that Twitter activity builds gradually during the anticipation of the eclipse, peaks at the height of the eclipse, then evaporates quickly after the eclipse is over (basically, what we’d expect).
Conclusion - September 23, 2017:
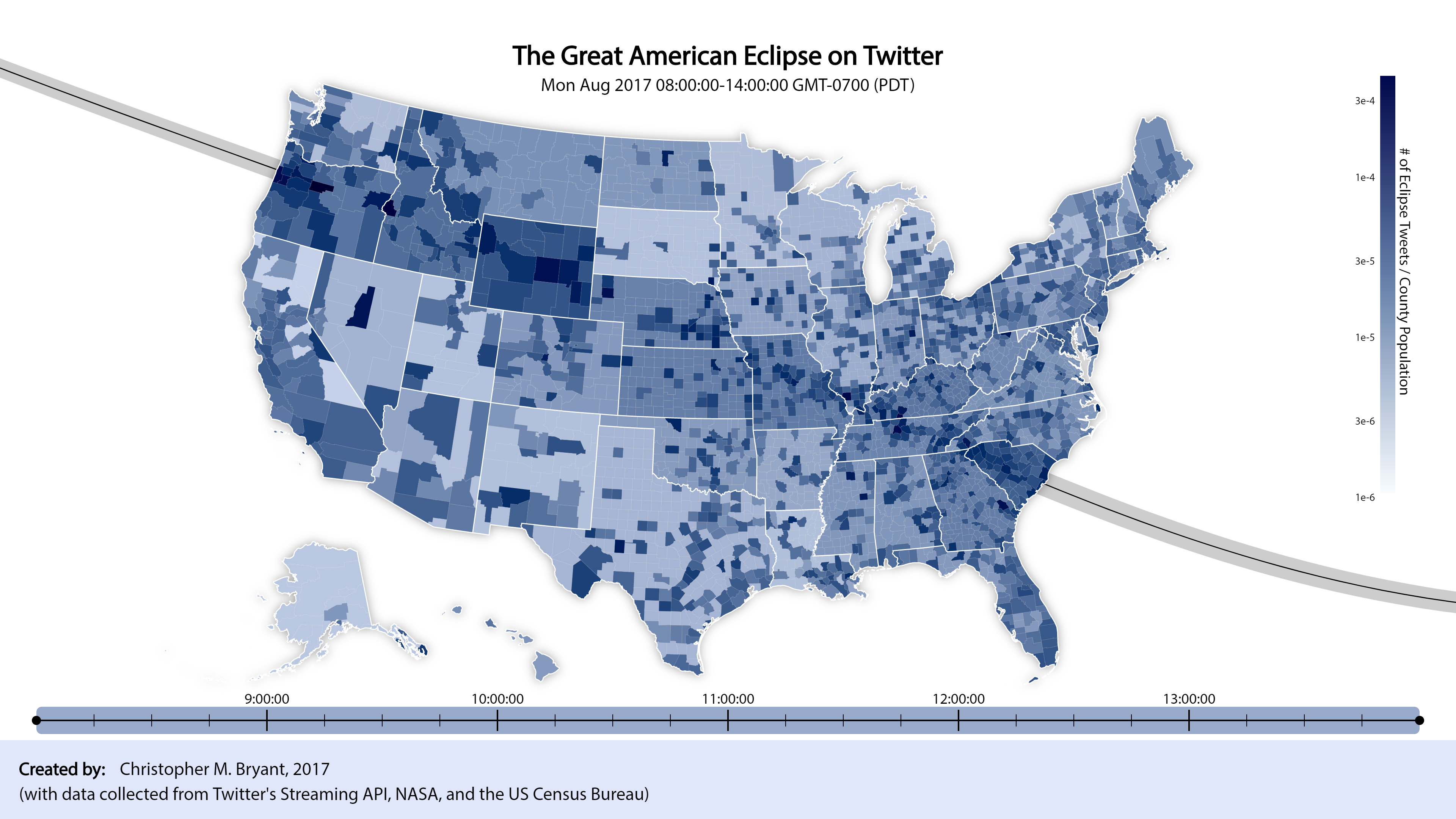
I’m very pleased with how this project turned out! Using only the locations and times of geo-tagged tweets containing the words “eclipse” or “sun”, we were able to illuminate two discinct effects: 1) the path traced by the region of totality, and 2) the movement of the shadow of the partial eclipse as it wiped across the United States. With just a visualization of simple social media data, we have constructed a rough, but reasonable model of a real astronomical event and part of its impact on the people who experienced it. In the interactive desktop version of the full time-spectrum map, we can zoom into specific locations, compare them to the region of totality, and actually read the tweets posted by people regarding their experience of the eclipse. My personal experience watching the total solar eclipse in Oregon was certainly life-changing, so it gives me pleasure to glimpse how the eclipse affected the lives of other individuals in ways small or large.
{kind=link}
If I were to continue developing this project, however, there are still several aspects of it I would change. Firstly, though this project taught me a huge amount about wrangling data and using new programming languages, my web-development skills are not as strong as they could be. Ideally, I would modify the interactive version of the map so that it functions like a proper website (resizing correctly, working on mobile, etc.). Additionally, I would like for the tweet point objects on the map to link to embedded versions of the actual tweets to which they refer, rather than redirecting to a Twitter search page for the tweet in question. Next, I would also like the timeline version of the visualization to be interactive, such that the plotted block of time can be stretched and dragged manually; however, this would require that I rethink the data plotting mechanism. Currently, I prepare all the data first in Python by calculating it for a fixed-length block of time, then load it into JavaScript to be accessed and plotted. If I were to enable timeline interactivity, I would need some way of preparing all the data natively in JavaScript and in real-time (a feat which I think is possible, but beyond my current abilities). In the more short-term, I would like to find a more efficient way to export all the pre-calculated SVG frames as PNGs. (To make my video, I could only export 10 frames at a time before the HTML page would no longer load, which is, I am pretty sure, a failure of my particular implementation of data-queueing in d3.)
Lastly, since my analysis of the totality path-shape and partial eclispe shadow-movement has been largely qualitative, I would like to work on a more quantitative approach to analyze my results. Perhaps a version of linear least squares regression can plot a best-fit line through the visualized path of totality for comparison with the true path. I suspect, however, that I may need more sophisticated machine learning techniques to adequately find the path, and especially to analyze the subtle effect of the moving partial eclipse shadow.
If you’d like to see the code I wrote for this project, here it is:
- EclipseTracker.ipynb: for acquiring the Twitter data
- HistogramAnalysis.py: for making quick histograms of data distributions
- TweetDataFrame.py: for doing the bulk of the data processing
- totalityNASA2JSON.py: for generating eclipse path GeoJSON files
- EclipseChoropleth_Interactive.html: for creating the interactive map
- EclipseChoroplethVideo.html: for creating map video frames